
In the history of digital evolution, one very apparent benefit gained by organizations was (and still is) the access and control over their data, and lots of it. No longer did companies need to rely strictly on paid service providers that specialize in collecting, analyzing, and interpreting the companies’ actions and efforts to better understand the market’s corresponding responses, reactions, as well as, projections for the future. Now, they too were able to easily, and in near real-time, generate, collect, and access data and analytics, to do with them as they wish.
First generation of data management
While acknowledging and understanding the potential value of data might have been obvious and easy to come by, the actual realization of its value would take a wide-reaching initiative, learnings, and time. At the start of it, companies needed to bring order and meaning to the data that was being generated. The logical first step was to collect and classify the data from all available sources, such as
systems, transactional records, access logs, web analytics, etc. This led to OLAP(online analytical processing) based databases or the first generation of data warehouses, while ETL (extract, transform, load) jobs provided the ingestion of data, and reporting, modeling, and hypothetical tools were laid on top of the pipeline to enable access, visualization, and analysis of the datasets.
Cloud adoption and evolution of data warehouses to data lakes
While there are many benefits of data warehousing, it did not prove to be very conducive to rapid scaling. Therefore, corporations needed more scalable approach to collect and process the ever expanding volume of data, requiring data management principles to evolve. The four Vs of big data (volume, velocity, variety and veracity) were considered while solutioning the data pipelines.
Cloud adoption, MapReduce, micro batching, stream processing, and other technical advancements helped to push the boundaries of operational data management techniques and principles to form data lakes. They enabled processing and storing of huge amounts of unstructured data, shifting the responsibilities of orchestration and transformation of the datasets closer to the consumption side of the data management organization structure.
There were also significant developments in the analytical data management front:
Web analytics and their supporting algorithms matured over time to form plotting and extrapolation of graphs, enabling training of data for machine learning, and further developing into the makings of deep neural networks.
Monetization and valuation of data became a common practice with the enablement and access to causality, and their corresponding weighted data and measures.
Even sentiment, affinity, and loyalty analysis using metrics from social media engagements and qualitative studies offered insights for organizations and individuals (especially for public figures or influencers) as a way of measuring their standing and effectiveness with their target audience.
A discoverable and composable data management platform
The organization’s ability to successfully: read the market accurately and promptly, anticipate the rising trends or a change in direction, and minimize the reaction/response time and impact to disruptions and disruptors, can differentiates the leaders from the rest of the industry. And performing well in the above areas requires an organization to have meaningful, actionable, and timely data at their fingertips at all times, demanding faster and shorter data management lifecycle – the next generation in data management evolution, data fabric.
A data fabric is more of a design concept enabled by “weaving” a variety of tools and technologies available in the market to collect, store, catalog/organize, integrate, process/transform, and infuse data for consumption in order to continuously optimize 1) the decisions being made, and 2)benefits of actions taken by the business.
A data fabric operates on an abstraction layer, and can be characterized by the following notions:
- An integrated layer of data and connecting processes
- Semantic inferences and active metadata discovery
- Knowledge graphs
- Composable by design
- Spans across all applications and platforms of the organization
- Follows a metadata driven approach
Data fabric architecture
While data warehouse and data lakes focused on improving data quality, the data fabric focuses on information quality and its accessibility. The following layers of data fabric help organizations fulfill those needs.
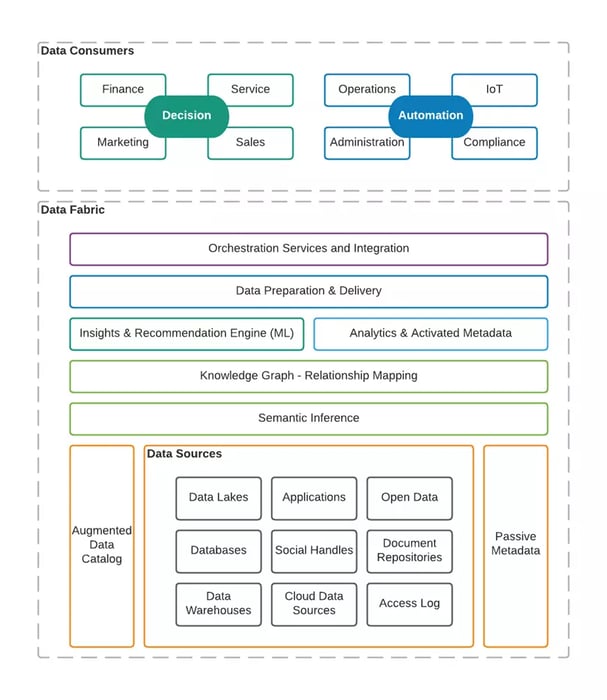
Data sources
The IT landscape of most companies are made of various types of data stores and enterprise software systems. The Data fabric’s goal is to bring all such siloed information together, no matter the source:
-
relational databases or non-relational databases
-
data warehouses or data lakes
-
various cloud sources
-
streams from social media handles
-
web analytics streams and various data pipelines
-
logs from applications
-
spreadsheets, word documents, emails
-
unstructured data sources
-
3rd party data service providers
-
data from enterprise systems, etc.
Data fabric, hence, needs to continuously collect information from various types of sources, and account for transformation and storage of various formats.
Data catalog and passive metadata associations
Cataloging the datasets and associating the datasets with their design based and runtime metadata is more of a manual effort. Subject matter experts owning each of those data sources should chime in to annotate the datasets.
The catalog can be further updated with ML based tools; profiling the data and pattern matching to identify any further insights; preparing the augmented data catalog.
Semantic inference
Once the datasets are collected, AI/ML based algorithms are leveraged to further scan across the data sets and attributes. This process helps in identifying semantic relationships between data entities or attributes of data entities. Also the entities or attributes are appropriately associated with standardized names and definitions which the entire organization can use in common to avoid any ambiguity or confusion.
For example, a travel sector organization where there are siloed databases of aircrafts, airports and runways will be able to join across datasets to answer such questions as – “Find airports that can land a C-5 cargo plane“.
Knowledge graph
A knowledge graph (can also be named a semantic inference graph) is a visualization capability over all semantically associated datasets. This helps the consumers of data fabric to query across various datasets with either, direct or indirect relationships, filters, and aggregated records as needed for analysis.
Active metadata
The augmented data catalog and passive metadata shed new light on the information and insights provided by the data collections. The data that was generated or collected by digitization of business processes may now show usefulness in many areas never thought of in the past.
Activating metadata is the process of leveraging AI/ML based insights and recommendation engine to continually look into the relevance of data records, associating them with usage, or ranking the records within the datasets. Improving the quality of information is the key purpose of metadata activation and making them actionable.
For example, an e-commerce platform provider would be able to provide their merchants with insights regarding what may help them improve their sales – product quality, packaging, pricing, delivery speed or mode. This is only possible by learning customer purchases, related ratings and reviews, and associating them with each merchant, delivery partners, competitive products, customer segment, etc., as well as associating each aspect with appropriate metadata tags.
Package and publish
All the knowledge collected or inferred is of no good use unless it is appropriately packaged according to the needs of its consumers. The functional data preparation and delivery layer of data fabric is just that. Composition, aggregation, grouping, or filtering is done at this layer through self-service interface exposed to the consumers. Low-code or no-code based platforms come in handy in such areas, empowering non-technical users.
Orchestration and integration layer, on the other hand, is responsible for onboarding the consumers and providing endpoints or interfaces through which they can access the information. To the decision makers, the layer may provide live report dashboards, notifications over email, push alerts, etc. For automation platforms or IoT consumers, the layer exposes data through web services or streams; letting those systems or devices trigger appropriate actions.
How can an organization go about building a data fabric?
Data fabric is not a plug-and-play product, but it is a state of data maturity reached with a set of practices, tools, and experts who work together to serve the decision makers and automate interfaces’ or IoT devices’ ability to access data containing meaningful and actionable insights. In order to set up a data fabric, an organization needs the following.
- Organization wide awareness and alignment
- Subject matter experts (SMEs) with the domain knowledge
- SMEs on AI & ML to set up
- Augmented data catalogs
- Semantic inferences
- Insights and recommendation engine
- SMEs on cloud, multi-cloud architectures – building each data fabric layers
- DevSecOps and MLOps rolling out the workloads
Dimiour is an IT solutions provider with extensive experience in technology consulting across AI, ML, MLOps, data science, analytics, DataOps, multi-cloud and DevSecOps. Dimiour can enable organizations to assess their current state and help design and execute the roadmap to a data fabric.
References
- https://www.ibm.com/analytics/data-fabric
- https://www.gartner.com/smarterwithgartner/data-fabric-architecture-is-key-to-modernizing-data-management-and-integration
- https://www.ibm.com/downloads/cas/WNBGAWZ1
- https://www.talend.com/resources/what-is-data-fabric/
- https://emtemp.gcom.cloud/ngw/globalassets/en/publications/documents/5-key-actions-for-it-leaders-for-better-decisions.pdf
- https://www.k2view.com/what-is-data-fabric
- https://www.collibra.com/us/en/blog/what-is-an-augmented-data-catalog
- https://www.researchgate.net/publication/3297947_Protection_of_Database_Security_Via_Collaborative_Inference_Detection#pf3
- https://bigid.com/blog/what-is-active-metadata/
Related Tags
| data fabric companies | data fabric architecture | cloud data fabric |
| data fabric provider | data fabric vendors |
data fabric implementation
|
|
data fabric software solutions
|
data warehouse |
data fabric solutions
|
|
data warehouse solution providers
|
data warehouse service providers
|
data fabric solutions for your business
|
|
data lakes
|
data fabric technology
|
data lake service providers
|
|
enterprise data lake solutions
|
data lake architecture
|
cloud adoption
|
|
composable data management
|
composable data management platform
|
knowledge graph machine learning
|
|
knowledge graph solutions
|
knowledge graph applications
|
knowledge graph
|
|
artificial intelligence services companies
|
machine learning development services providers
|
machine learning development company
|
|
machine learning agency
|
machine learning services
|
artificial intelligence
|
|
artificial intelligence services
|
artificial intelligence services
|
machine learning
|
|
mlops
|
mlops platform
|
mlops platform architecture
|
|
data science services companies
|
data science platform architecture
|
dataops managed services and consulting solutions
|
|
data science consulting firms
|
data science
|
dataops
|
|
dataops solutions
|
dataops implementation
|
dataops platform
|
|
data science service providers
|
dataops platform solutions
|
